![]()
Subscribe to Google group to keep yourself updated.
Why 2nd OGB-LSC?
Machine learning (ML) over large-scale graph data (e.g., graphs with billions of edges) has a huge impact. At KDD Cup 2021, we organized the 1st OGB Large-Scale Challenge (OGB-LSC), where we provided large and realistic graph ML tasks. Our KDD Cup attracted huge attention from graph ML community (more than 500 team registrations across the globe, ~150 teams participated), facilitating innovative methods being developed to yield significant performance breakthrough. However, the problem of machine learning over large graphs is not solved yet, and it is important for the community to engage in a focused multi-year effort in this area (like ImageNet and MS-COCO).
For the NeurIPS 2022 competition track, we organize the 2nd OGB-LSC (referred to as OGB-LSC 2022) around the OGB-LSC datasets, which will drive forward method development and allow for tracking progress Importantly, we have updated two out of the three datasets based on the lessons learned from our KDD Cup, so that the resulting datasets are more challenging and realistic.
Overview of OGB-LSC 2022
We provide three OGB-LSC datasets that are unprecedentedly large in scale and cover prediction at the level of nodes, links, and graphs, respectively. An illustrative overview of the three OGB-LSC datasets is provided below.
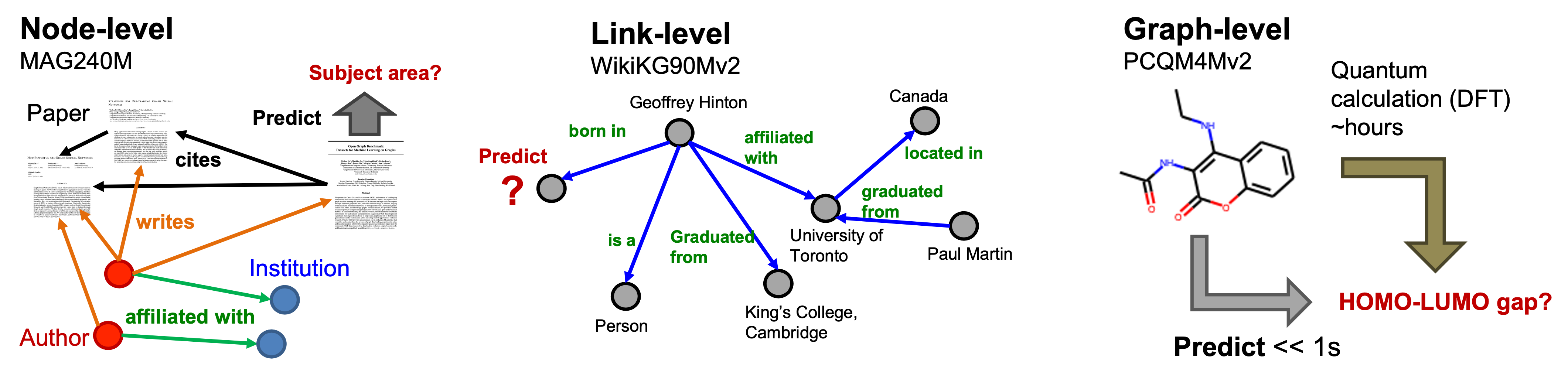
- MAG240M is a heterogeneous academic graph, and the task is to predict the subject areas of papers situated in the heterogeneous graph (node classification).
- WikiKG90Mv2 is a knowledge graph, and the task is to impute missing triplets (link prediction).
- PCQM4Mv2 is a quantum chemistry dataset, and the task is to predict an important molecular property, the HOMO-LUMO gap, of a given molecule (graph regression).
There are two kinds of test sets: test-dev and test-challenge. For this NeurIPS challenge, please use test-challenge. The test-dev is used for the public leaderboards, where the community can evaluate their model performance throughout the year. We encourage test-dev submissions even during the NeurIPS competition, but in order to be qualified for the leaderboards, we require public code and technical report.
More details can be found here.
Paper
Details about our datasets and our initial baseline analysis are described in our OGB-LSC paper. If you use OGB-LSC in your work, please cite our paper (Bibtex below)
@article{hu2021ogblsc,
title={OGB-LSC: A Large-Scale Challenge for Machine Learning on Graphs},
author={Hu, Weihua and Fey, Matthias and Ren, Hongyu and Nakata, Maho and Dong, Yuxiao and Leskovec, Jure},
journal={arXiv preprint arXiv:2103.09430},
year={2021}
}
OGB-LSC Team and Contact
The OGB-LSC team can be reached at ogb-lsc@cs.stanford.edu. For discussion or general questions about the datasets, use our Github discussion. For questions about our code, use our Github issues. Subscribe to our Google group to keep yourself updated with any changes and updates from us.
We acknowledge Adrijan Bradaschia (Stanford) for setting up the server and the test submission page. We also acknowledge the DGL Team for helping us host our datasets on AWS, which allows much faster downloading of the datasets.





