![]()
KDD Cup 2021 has been concluded. This is an archive page.
Updated page is here. Competition results announced here.
Why a Large-Scale Graph ML Competiton?
Machine Learning (ML) on graphs has attracted immense attention in recent years because of the prevalence of graph-structured data in real-world applications. Modern application domains include web-scale social networks, recommender systems, hyperlinked web documents, knowledge graphs (KGs), as well as molecule simulation data generated by the ever-increasing scientific computation. These domains involve large-scale graphs with billions of edges or a dataset with millions of graphs. Deploying accurate graph ML at scale will have a huge practical impact, enabling better recommendation results, improved web document search, more comprehensive KGs, and accurate ML-based drug and material discovery. However, community efforts to advance state-of-the-art in large-scale graph ML have been extremely limited. In fact, most of graph ML models have been developed and evaluated on extremely small datasets.
Handling large-scale graphs is challenging, especially for state-of-the-art expressive Graph Neural Networks (GNNs) because they make prediction on each node based on the information from many other nodes. Effectively training these models at scale requires sophisticated algorithms that are well beyond standard SGD over i.i.d. data. More recently, researchers improve model scalability by significantly simplifying GNNs, which inevitably limits their expressive power.
However, in deep learning, it has been demonstrated over and over again that one needs big expressive models and train them on big data to achieve the best performance. In graph ML, the trend has been the opposite—models get simplified and less expressive to be able to scale to large graphs. Thus, there is a massive opportunity to move the community to work with realistic and large-scale graph datasets and move the state of the field forward to where it needs to be.
Overview of OGB-LSC
Here we propose a large-scale graph ML competition, OGB Large-Scale Challenge (OGB-LSC), to encourage the development of state-of-the-art graph ML models for massive modern datasets. Specifically, we present three datasets: MAG240M, WikiKG90M, and PCQM4M, that are unprecedentedly large in scale and cover prediction at the level of nodes, links, and graphs, respectively. Each dataset offers an independent task, and the awardees will be selected separately for each dataset. We will announce the top 3 winning teams for each of the datasets, and they will be given opportunities to present their solutions during the KDD Cup workshop.
An illustrative overview of the three OGB-LSC datasets is provided below.
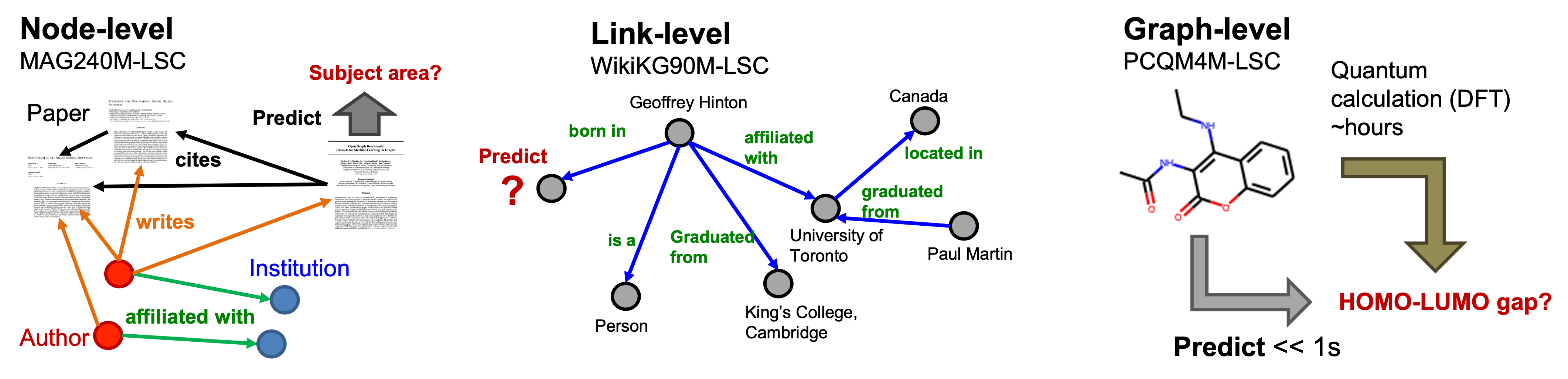
- MAG240M is a heterogeneous academic graph, and the task is to predict the subject areas of papers situated in the heterogeneous graph (node classification).
- WikiKG90M is a knowledge graph, and the task is to impute missing triplets (link prediction).
- PCQM4M is a quantum chemistry dataset, and the task is to predict an important molecular property, the HOMO-LUMO gap, of a given molecule (graph regression).
For each dataset, we carefully design its prediction task and data split so that achieving high prediction performance on the task will have direct impact on the corresponding application. Further details are provided in each dataset page.
The dataset statistics as well as basic information are summarized below, showing that our datasets are extremely large.
| Task category | Name | Package | #Graphs | #Total nodes | #Total edges | Task Type | Metric | Download size |
|---|---|---|---|---|---|---|---|---|
| Node-level | MAG240M | >=1.3.0, <=1.3.1 | 1 | 244,160,499 | 1,728,364,232 | Multi-class classification | Accuracy | 167GB |
| Link-level | WikiKG90M† | >=1.3.0, <=1.3.1 | 1 | 87,143,637 | 504,220,369 | KG completion | MRR | 94GB |
| Graph-level | PCQM4M† | >=1.3.0, <=1.3.1 | 3,803,453 | 53,814,542 | 55,399,880 | Regression | MAE | 58MB‡ |
†: The WikiKG90M and PCQM4M datasets have been deprecated after the KDD Cup 2021. The updated datasets are WikiKG90Mv2 and PCQM4Mv2 (available for ogb>=1.3.3).
‡: The PCQM4M dataset is provided in the SMILES strings. After processing them into graph objects, the eventual file size will be around 8GB.
All of these datasets can be downloaded and prepared using our ogb Python package.
The model evaluation and test submission file preparation are also handled by our package.
The usage is described in each dataset page. Please install/update it by:
pip install -U ogb
# Make sure below prints the required package version for the dataset you are working on.
python -c "import ogb; print(ogb.__version__)"
In our paper, we further perform an extensive baseline analysis on each dataset, implementing simple baseline models as well as advanced expressive models at scale. We find that advanced expressive models, despite requiring more efforts to scale up, do benefit from large data and significantly outperform simple baseline models that are easy to scale. All of our baseline code is made publicly available to facilitate public research.
Overall, our KDD Cup will encourage the community to develop and scale up expressive graph ML models, which can yield significant breakthroughs in the respective domains. We hope OGB-LSC at KDD Cup 2021 will serve as an “ImageNet Large Scale Visual Recognition Challenge” in the field of graph ML, encouraging the community to work on realistic and large-scale graph datasets and significantly advance the state-of-the-art.
Paper
Details about our datasets and our initial baseline analysis are described in our OGB-LSC paper. If you use OGB-LSC in your work, please cite our paper (Bibtex below)
@article{hu2021ogblsc,
title={OGB-LSC: A Large-Scale Challenge for Machine Learning on Graphs},
author={Hu, Weihua and Fey, Matthias and Ren, Hongyu and Nakata, Maho and Dong, Yuxiao and Leskovec, Jure},
journal={arXiv preprint arXiv:2103.09430},
year={2021}
}
OGB-LSC Team and Contact
The OGB-LSC team can be reached at ogb-lsc@cs.stanford.edu. For discussion or general questions about the datasets, use our Github discussion. For questions about our code, use our Github issues. Subscribe to our Google group to keep yourself updated with any changes and updates from us.
We acknowledge Adrijan Bradaschia (Stanford) for setting up the server and the test submission page. We also acknowledge the DGL Team for helping us host our datasets on AWS, which allows much faster downloading of the datasets.






Partners
 Amit Bleiweiss
Amit Bleiweiss Intel |
 Benjamin Braun
Benjamin Braun Intel |