![]()
KDD Cup 2021 has been concluded. This is an archive page.
Updated page is here. Competition results announced here.
Important: WikiKG90M has been deprecated. Use WikiKG90Mv2 instead.
Learn about WikiKG90M-LSC and Python package
- Dataset: Learn about the dataset and the prediction task.
- Python package tutorial
- Dataset object: Learn about how to prepare and use the dataset with our package.
- Performance evaluator: Learn about how to evaluate models and save test submissions with our package.
- Initial baseline code: Learn about our initial baseline experiments.
- Discussion forum: Ask questions and make discussion about the dataset.
Dataset: Predicting missing facts in a knowledge graph
Practical Relevance:
Large encyclopedic Knowledge Graphs (KGs), such as Wikidata [1] and Freebase [2], represent factual knowledge about the world through triplets connecting different entities, e.g., (Geoffrey Hinton, citizen of, Canada). They provide rich structured information about many entities, aiding a variety of knowledge-intensive downstream applications such as information retrieval, question answering, and recommender systems.
However, these large KGs are known to be far from complete, missing many relational information between entities.
Using ML to automatically impute missing triplets significantly reduces the manual curation of knowledge and provides a more comprehensive KG, which in turn improves the aforementioned downstream applications.
Overview: WikiKG90M-LSC is a Knowledge Graph (KG) extracted from the entire Wikidata knowledge base. The task is to automatically impute missing triplets that are not yet present in the current KG. Accurate imputation models can be readily deployed on the Wikidata to improve its coverage.
Graph:
Each triplet (head, relation, tail) in WikiKG90M-LSC represents an Wikidata claim, where head and tail are the Wikidata items, and relation is the Wikidata predicate. We extracted triplets from the public Wikidata dump downloaded at three time-stamps: September, October, and November of 2020, for training, validation, and testing, respectively.
We retain all the entities and relations in the September dump, resulting in 87,143,637 entities, 1,315 relations, and 504,220,369 triplets in total.
In addition to extracting triplets, we provide text features for entities and relations. Specifically, each entity/relation in Wikidata is associated with a title and a short description, e.g., one entity is associated with the title Geoffrey Hinton and the description computer scientist and psychologist.
Similar to MAG240M-LSC, we provide RoBERTa embeddings [4,5] for all the entities and relations.
Prediction task and evaluation metric:
The task is the KG completion, i.e., given a set of training triplets, predict a set of test triplets.
For evaluation, for each test triplet, (head, relation, tail), we corrupt tail with randomly-sampled 1000 negative entities tail_neg, such that (head, relation, tail_neg) does not appear in the train/validation/test KG.
The model is asked to rank the 1001 candidates (consisting of 1 positive and 1000 negatives) for each triplet and predict the top 10 entities that are most likely to be positive. The goal is to rank the ground-truth positive entity as high in the rank as possible, which is measured by Mean Reciprocal Rank (MRR).
Data split: We split the triplets according to time, simulating a realistic KG completion scenario of imputing missing triplets not present at a certain timestamp. Specifically, we construct three KGs using the aforementioned September, October, and November KGs, where we only retain entities and relation types that appear in the earliest September KG. We use the triplets in the September KG for training, and use the additional triplets in the October and November KGs for validation and test, respectively.
References
[1] Vrandečić, D., & Krötzsch, M. (2014). Wikidata: a free collaborative knowledgebase. Communications of the ACM, 57(10), 78-85.
[2] Bollacker, K., Evans, C., Paritosh, P., Sturge, T., & Taylor, J. (2008, June). Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data (pp. 1247-1250).
[3] Reimers, N., & Gurevych, I. (2019). Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084.
[4] Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L. & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
[5] Reimers, N., & Gurevych, I. (2019). Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084.
License: CC-0
Python package: Dataset object
The dataset object handles downloading and easy access to the graph and its features. Below we go through its basic usage.
- Download and extract data
Download and process dataset under the specified ROOT directory (default to dataset/).
This takes a while (several hours to a day) in the first run, so please be patient.
After decompression, the file size will be around 159GB.
from ogb.lsc import WikiKG90MDataset
dataset = WikiKG90MDataset(root = ROOT)
- Get basic dataset statistics
print(dataset.num_entities) # number of entities
print(dataset.num_relations) # number of relation types
print(dataset.num_feat_dims) # dimensionality of entity/relation features.
- Get training triplets
Each triplet consists of (head, relation, tail). In the following, we abbreviate it as (h, r, t).
Training triplets can be obtained as follows.
train_hrt = dataset.train_hrt # numpy ndarray of shape (num_triplets, 3)
i = 1234
print(train_hrt[i]) # get i-th training triplet [h, r, t]
- Get entity features
Entity features are extremely large (768-dimensional vectors for the 87M entities).
The features are saved as numpy’s .npy format in half precision (np.float16). The raw file is available at ROOT/wikikg90m_kddcup2021/processed/entity_feat.npy and has 125GB.
In our package, we use numpy’s read-only memmap mode so that the features can be loaded in a CPU-memory-efficient way.
In the memmap mode, each entity feature is not loaded into CPU memory from disk until it is explicitly accessed by your program.
Below are examples.
# get i-th entity feature
i = 1234
print(dataset.entity_feat[i]) # only i-th data is loaded into memory
# get the feature matrix storing features of entities in idx_arr
idx_arr = np.array([1,10,100,1000,10000])
print(dataset.entity_feat[idx_arr]) # only the 5 data is loaded into memory
Here each data access is a disk access, which could be a bit slow. If you have sufficient CPU memory, you could also load the entire feature matrix into CPU memory at the beginning and enjoy fast RAM data access from there. Note: Do not run the following unless you have 200GB+ CPU memory!
# load the entire data (125GB) into CPU memory
feat_in_memory = dataset.all_entity_feat # this takes a while
# Fast RAM access.
print(feat_in_memory[i])
print(feat_in_memory[idx_arr])
- Get relation features
# both read the entire relation features (only 2MB) into CPU memory
print(dataset.relation_feat)
print(dataset.all_relation_feat)
- Get a prediction task
For validation and testing, the goal is to predict the correct tail given head and relation. Hence, the prediction can be written as head,relation->tail, or h,r->t in short.
Below we illustrate how we set up the h,r->t prediction task from the original validation/test triplets (on the very left of the figure).
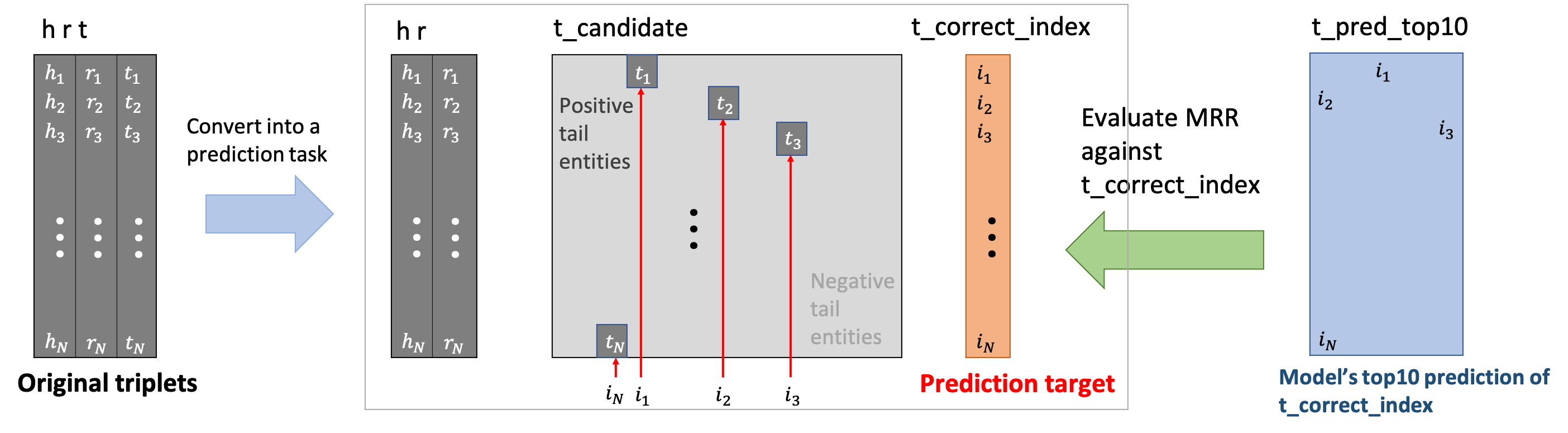
As illustrated, we convert the original hrt matrix into hr, t_candidate, and t_correct_index, defined below.
hr: numpy ndarray of shape (num_validation_triplets, 2)i-th row storesi-th (h,r)
t_candidate: numpy ndarray of shape(num_validation_triplets, 1001)i-th row (i.e.,t_candidate[i]) storesi-th candidates for the tail entities (1001 candidates in total, out of which one is a positive entity).- Note that
t_candidateis a giant matrix (13GB), sonumpy’s read-onlymemmapmode is used. - In the
memmapmode, each row is not loaded into CPU memory from disk until it is explicitly accessed by your program. Below are examples.
t_correct_index: numpy array of shape(num_validation_triplets,)i-th element (i.e.,t_correct_index[i]) stores the index (0<= index < 1001) of the true tail entity int_candidate[i].- Therefore, (
h[i],r[i],t_candidate[i][t_correct_index[i]]) is the true validation triplet.
The task is for the model to accurately predict t_correct_index given hr and t_candidate. Specifically, the model predicts t_pred_top10, defined as follows.
t_pred_top10: numpy ndarray of shape(num_validation_triplets, 10)t_pred_top10[i][rank]stores therank-th predicted index (0<= index < 1001) of the tail entity int_candidate[i].- In other words, the model predicts that (
h[i],r[i],t_candidate[i][t_pred_top10[i][rank]]) is therank-th likely triplets among the 1001 candidate triplets.
The goal is for the model to rank t_correct_index[i] as high as possible within t_pred_top10[i], which is measured by Reciprocal Rank (i.e., inverse of the rank). If t_correct_index[i] is not ranked within t_pred_top10[i], the model receives the score of 0. The Overall performance is measured by Mean Reciprocal Rank (MRR), which is commonly-used in the KG completion literature.
For validation, we provide all hr, t_candidate, and t_correct_index, which can be accessed as follows.
valid_task = dataset.valid_dict['h,r->t'] # get a dictionary storing the h,r->t task.
hr = valid_task['hr']
t_candidate = valid_task['t_candidate']
t_correct_index = valid_task['t_correct_index']
For test, we only provide hr and t_candidate, and t_correct_index is hidden.
test_task = dataset.test_dict['h,r->t'] # get a dictionary storing the h,r->t task.
hr = test_task['hr']
t_candidate = test_task['t_candidate']
# test_task['t_correct_index'] is hidden and not provided
Python package: Performance evaluator
We provide an evaluator to evaluate and save model’s prediction in a standardized way. To evaluate train/validation performance, first prepare
t_pred_top10: numpy array of shape(num_validation_triplets, 10), defined as before.t_correct_index: numpy array of shape(num_validation_triplets, ), defined as before.
from ogb.lsc import WikiKG90MEvaluator
evaluator = WikiKG90MEvaluator()
input_dict = {}
input_dict['h,r->t'] = {'t_pred_top10': t_pred_top10, 't_correct_index', t_correct_index}
result_dict = evaluator.eval(input_dict)
print(result_dict['mrr']) # get mrr
To save your test submission, first prepare
t_pred_top10:np.arrayortorch.Tensorof shape(num_test_triplets, 10), defined as before except that the prediction is over the test triplets.dir_path: directory path (type:str) to save the test file (our package will create the directory if it does not exist). Test filet_pred_wikikg90m.npzwill be saved under the directorydir_path.
input_dict = {}
input_dict['h,r->t'] = {'t_pred_top10': t_pred_top10}
evaluator.save_test_submission(input_dict = input_dict, dir_path = dir_path)